Preamble
Previously I stated that the cost of using a virtual function has gone down, but I have been doing a bit more thinking on this and feel I should add a further comment.
Virtual functions are still not great
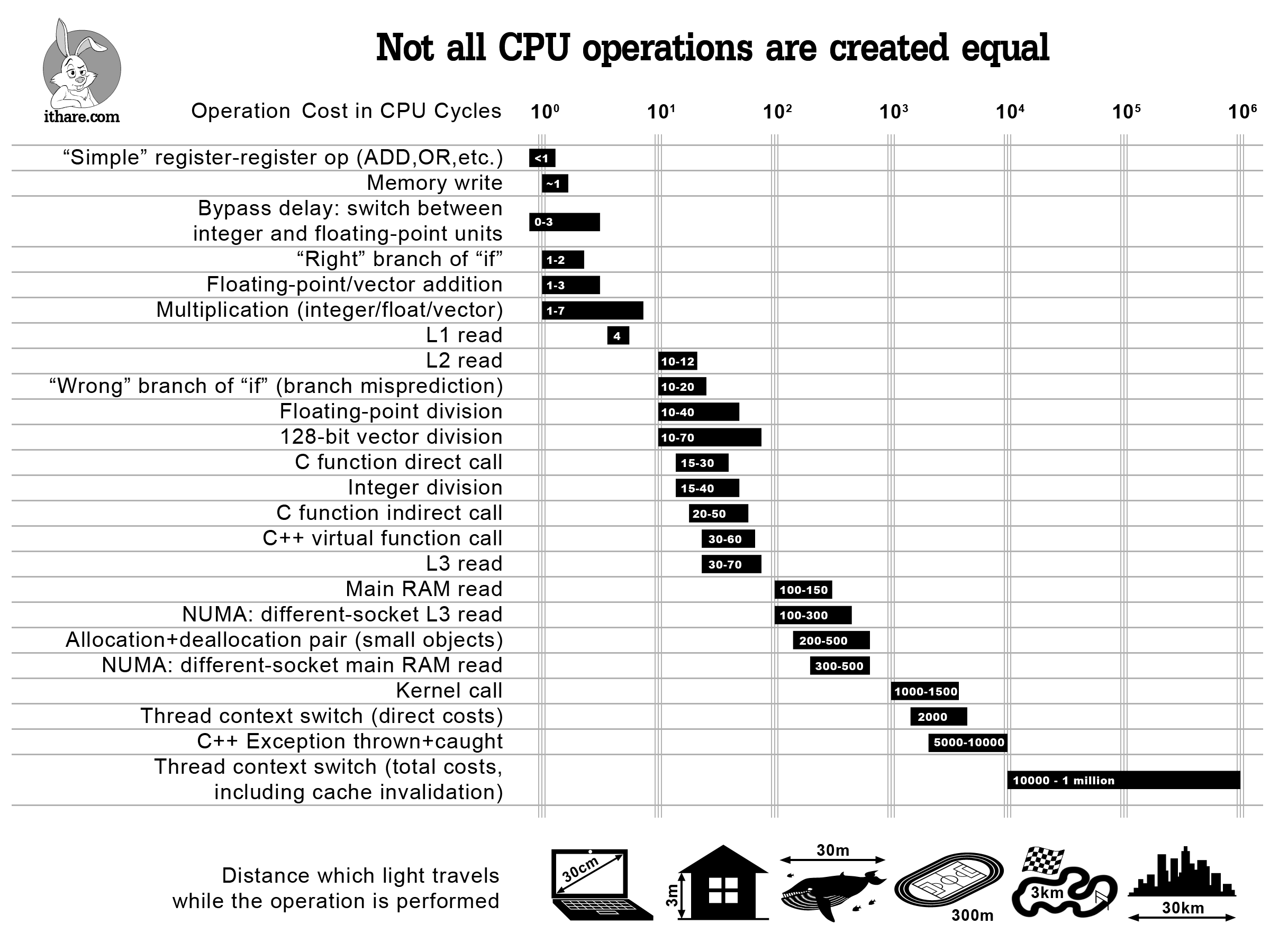
Yes the individual cost of calling a virtual function has gone down dramatically with faster ram, caches and cpu branch prediction and architecture (its about 2x the speed of a standard function), but the real cost of a virtual function appears to lie in what it actually does to the compilation of the code. Placing a virtual function call in the code stops the compiler from inlining/optimizing the code at that point.
It is probably simpler to consider, would you consider adding an ‘if’ to you code if it isn’t really needed. It 1) adds complexity, 2) increases latency. A virtual function does exactly the same.
Functionality provided by language features
Virtual functions provide a lot of functionality when writing the code but this can often be achieved using other C++ language features.
virtual functions – decoupling, delegation, code reuse, common interface variable.
functions – delegation.
classes – decoupling.
templates – code reuse.
type erasure – common interface variable.
So it might be worth considering using only the required language feature at the required time, in order to write cleaner code, and avoid the proliferation of class hierarchies in code.
A nice example of writing better code without virtual functions is shown here, I stole some of his ideas in this blog entry! :
Conclusion
Virtual functions are useful for runtime polymorphism, but often this is not required and really what is required is code reuse (templates). Virtual functions provide a lot of functionality, often more than needed.
Having said that, if you need a virtual function, don’t be afraid to use one! Its a wonderful feature of the language.
We are all STILL learning to write code!!!